Scaling OpenAI Chatbots: Best Practices for High Load

Scaling OpenAI Chatbots: Best Practices for High Load
Scaling OpenAI chatbots is all about ensuring they can handle heavy traffic without breaking down. Here's a quick summary of the key practices:
- Optimize Infrastructure: Use cloud platforms like Azure for seamless OpenAI integration, configure load balancers, and implement caching with tools like GPTCache.
- Manage API Performance: Monitor rate limits, batch requests, and use error recovery strategies like exponential backoff.
- Handle High Traffic: Set up queue systems (e.g., RabbitMQ), prioritize requests, and use asynchronous processing for smoother operations.
- Track Performance: Use tools like Datadog or CloudWatch to monitor response times, error rates, and traffic patterns in real time.
- Prepare for Spikes: Implement backup plans, fallback mechanisms, and auto-scaling to maintain service during peak loads.
Quick Comparison of Cloud Platforms for OpenAI Chatbots
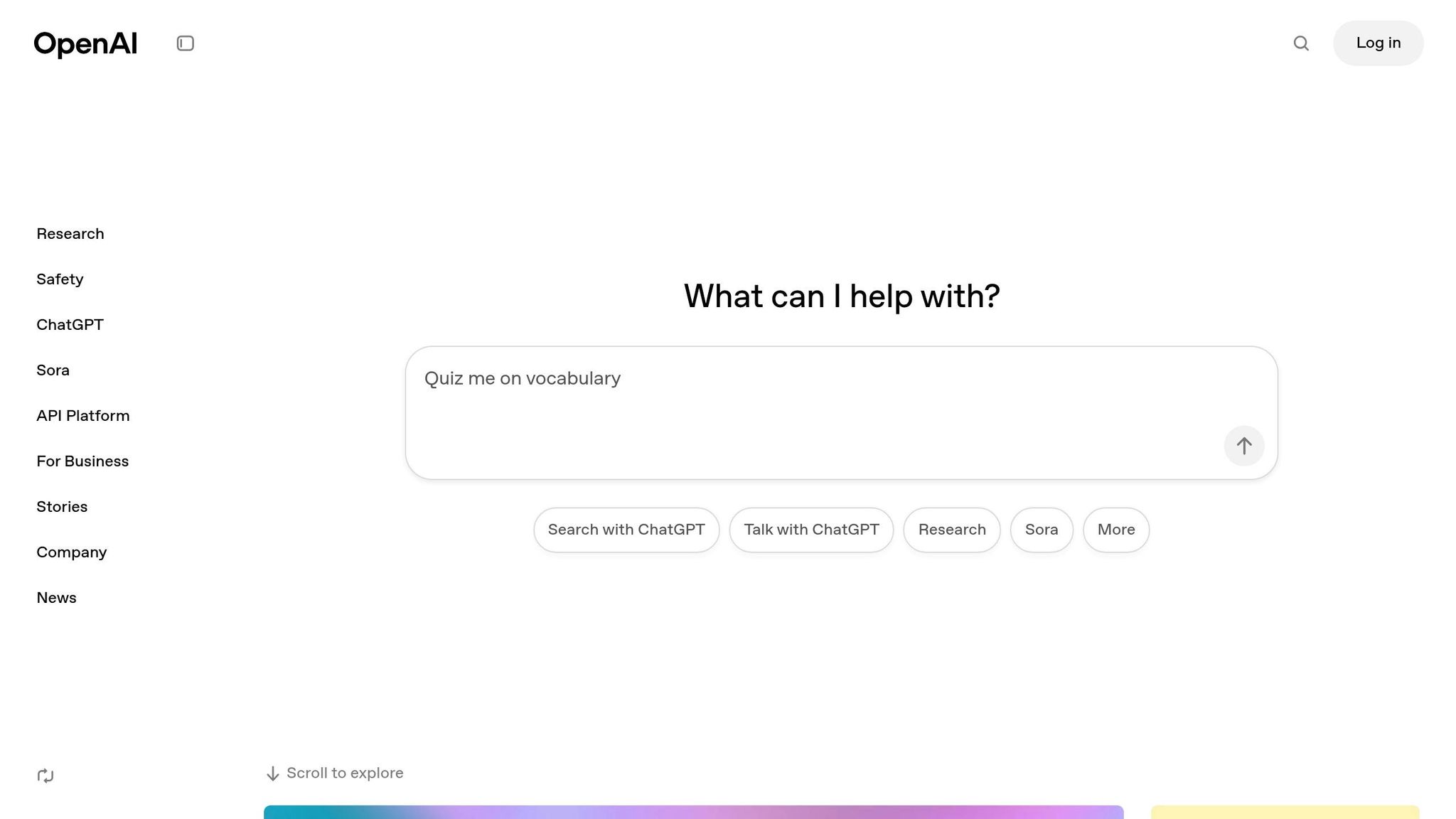
| Cloud Provider | Best Use Case | Key Benefits |
|---|---|---|
| Azure | OpenAI Models | Built-in OpenAI integration, Microsoft ecosystem support |
| AWS | Anthropic's Claude | Comprehensive AI tools, robust compute resources |
| Google Cloud | Gemini Models | Advanced ML tools, TensorFlow compatibility |
Scaling requires a mix of infrastructure optimization, proactive traffic management, and continuous monitoring. Follow these steps to ensure your chatbot performs reliably under any load.
Boost Your AI API Caching Load Balancing & Compression
Infrastructure Setup for Scale
A well-structured infrastructure is the backbone of a system that can handle peak loads without breaking down. This section focuses on the technical aspects needed to ensure smooth operations.
Cloud Platform Selection
Choosing the right cloud platform is critical for deploying OpenAI chatbots. Here’s a comparison of the top three providers:
| Cloud Provider | Best Use Case | Key Benefits |
|---|---|---|
| Azure | OpenAI Models | Built-in OpenAI integration, strong Microsoft ecosystem support |
| AWS | Anthropic's Claude | Comprehensive AI tools and robust compute resources |
| Google Cloud | Gemini Models | Advanced machine learning tools and TensorFlow compatibility |
The platform you choose directly affects costs and performance. For example, OpenAI spent $70 million on cloud services in 2020 before partnering exclusively with Microsoft. These platforms operate on a pay-as-you-go model, so it’s essential to align the choice with your existing infrastructure and scaling needs. Azure stands out for its seamless OpenAI integration, making it ideal for OpenAI-based chatbots.
Once the platform is chosen, load balancing and caching become the next priorities.
Load Balancer Configuration
Load balancers are essential for maintaining consistent performance during traffic surges. HAProxy is a popular choice for managing chatbot infrastructure, offering advanced traffic management and reliability features.
Key aspects to consider when configuring load balancers:
- Session Persistence: Sticky sessions ensure ongoing conversations are routed to the same server, maintaining user experience.
- Health Monitoring: Regular health checks prevent traffic from being directed to servers that are down or malfunctioning.
- Dynamic Configuration: HAProxy’s RESTful Data Plane API allows real-time adjustments without disrupting operations.
"HAProxy is the best multi-purpose load balancer on the market." - Edgars V., Senior IT Specialist
After setting up the load balancer, caching becomes the next step to optimize response times and reduce costs.
Cache System Implementation
Caching is a powerful way to cut API expenses and improve response times. GPTCache offers advanced features compared to traditional systems like Redis:
| Feature | Traditional Cache (Redis) | GPTCache |
|---|---|---|
| Query Type | Exact key matches only | Supports semantic search |
| Storage Options | Limited to in-memory | Supports SQLite, MySQL, PostgreSQL, and more |
| Cost | Expensive for large datasets | Optimized for large language model (LLM) responses |
| Search Method | Key-based | Vector similarity search |
For the best results, configure GPTCache with a similarity threshold of 0.7. This strikes a balance between accuracy and cache hit rates.
"With GPTCache, you can cache your LLM responses with just a few lines of code changes, boosting your LLM applications 100 times faster." - James Luan, VP of Engineering, Zilliz
OpenAI API Performance Tips
Scaling OpenAI chatbots requires careful attention to API performance, especially during peak usage periods. Here's how to manage it effectively.
API Rate Limit Management
Rate limits are in place to ensure fair access and protect OpenAI's infrastructure. These limits vary depending on your monthly spending tier:
| Usage Tier | Monthly Spend Limit |
|---|---|
| Free | $100 |
| Tier 1 | $100 |
| Tier 2 | $500 |
| Tier 3 | $1,000 |
| Tier 4 | $5,000 |
| Tier 5 | $200,000 |
To make the most of your tier:
- Keep an eye on headers like x‑ratelimit‑remaining‑tokens and x‑ratelimit‑remaining‑requests.
- Plan request timing based on your tier's limits.
- Set user-specific quotas to prevent overuse or abuse.
Managing rate limits efficiently works well alongside batching requests for smoother API usage.
Request Batching Methods
Batch processing can improve efficiency and cut costs. OpenAI's Batch API, introduced in April 2024, brings several benefits:
- 50% discount on regular completions.
- Higher rate limits, allowing up to 250 million input tokens for GPT‑4T.
- Guaranteed results within 24 hours.
"The new Batch API allows to create async batch jobs for a lower price and with higher rate limits." – OpenAI Cookbook
Here’s how to make batching work for you:
- Format batch requests in JSONL with unique
custom_idvalues. - Schedule uploads during off-peak hours.
- Use polling to monitor completion status.
- Process results asynchronously for better workflow integration.
Batching not only optimizes performance but also lays the groundwork for handling errors effectively.
Error Recovery Systems
Reliable error handling is key to maintaining service quality. Here are some strategies to address common issues:
| Error Type | Recovery Strategy | Implementation |
|---|---|---|
| Rate Limits | Exponential backoff | Automate retries with gradually increasing delays |
| API Timeouts | Fallback models | Switch to backup models during downtime |
| Token Overages | Dynamic adjustment | Adjust max_tokens based on real-time usage patterns |
To avoid token overuse or other disruptions:
- Set up automated alerts to monitor usage.
- Use request queues to manage sudden traffic surges.
- Configure fallback solutions for critical functions.
- Regularly test and refine your recovery processes.
Proactive monitoring and robust recovery systems ensure smoother operations and higher reliability.
High Traffic Management
Efficiently handling high traffic goes beyond strong API performance and error recovery. Queue management and asynchronous processing play a key role in maintaining performance during traffic surges while making the most of available resources.
Queue System Setup
Queue systems prevent server overload by managing requests in an organized way. They ensure chatbots can handle heavy loads without compromising performance.
| Queue Type | Best Use Case | Key Benefits |
|---|---|---|
| Priority Queue | VIP customers, urgent issues | Faster response for critical requests |
| Circular Queue | Even workload distribution | Balanced server utilization |
| Skill-based Queue | Complex technical inquiries | Better resolution rates |
For example, the Pinoplast chat-service project successfully uses RabbitMQ with OpenAI's ChatGPT API. This setup includes separate input and output queues to streamline message flow and boost efficiency.
"Call queues mitigate this by providing customers with an estimated wait time, setting expectations and reducing the anxiety of waiting." - Bhavya Aggarwal and Jayadeep Subhashis, Sprinklr
Tips for optimizing queue performance:
- Use automatic retry mechanisms with 10-second delays.
- Limit retry attempts to 5 per request.
- Implement failover systems to ensure uninterrupted service.
- Regularly monitor queue depth and processing rates.
Once queues are in place to manage requests, asynchronous processing can take performance to the next level.
Async Processing Methods
Asynchronous processing allows chatbots to handle multiple conversations at once, keeping them responsive even during peak traffic. This approach not only improves user experience but also maximizes server efficiency.
Benefits of asynchronous processing:
- Faster response times for users.
- Better use of server resources.
- Ability to handle sudden traffic spikes.
- Greater scalability for the entire system.
"Asynchronous programming in Python allows for non-blocking operations, improving efficiency and responsiveness in applications, especially crucial in AI development."
To implement asynchronous processing, use tools like asyncio for concurrent tasks, establish robust error handling with try-except blocks, and monitor system resources to adapt to demand.
sbb-itb-7a6b5a0
Performance Tracking Systems
Effective monitoring helps prevent scaling issues when systems face heavy loads.
Key Performance Metrics
Keep an eye on response times, error rates, and API usage patterns. Focus on metrics like API latency and quota usage:
| Metric Category | Key Measurements |
|---|---|
| Response Time | API latency, user wait time |
| Error Tracking | Bit error rate (BER) |
| API Usage Patterns | API quota use, server load |
It's worth noting that bit error rates can be influenced by factors like transmission noise, interference, and signal distortion.
After defining these metrics, choose tools that deliver real-time data for better decision-making.
Setting Up Monitoring Tools
Pair your scaling strategies with tools that provide real-time insights and actionable data:
- Datadog: Offers real-time monitoring with over 750 integrations, custom metrics, and automated alerts.
-
New Relic: Features application performance monitoring (APM), full transaction tracking, and real user monitoring.
"New Relic gives us one platform that we can look at and get a complete picture. It's absolutely crucial." – Scott Favelle, Technology Director, Seven West Media
- CloudWatch: Integrates seamlessly with AWS, providing custom metrics, auto-scaling capabilities, and log aggregation.
Analyzing Traffic Patterns
Choosing the right tools is only part of the equation. Understanding traffic patterns is essential for scaling effectively. By analyzing these patterns, you can anticipate resource needs and avoid performance issues:
- Peak Usage Analysis: Track daily, weekly, and seasonal fluctuations to identify traffic spikes and their causes.
- Resource Utilization: Measure API quota usage, server capacity, and cache hit rates to optimize performance.
- Predictive Scaling: Use historical data to set automated scaling rules, ensuring your system can handle future demands.
Taking a proactive approach to traffic analysis helps your system adapt to both gradual changes and unexpected surges, ensuring smooth performance even during peak loads.
Implementation Guidelines
Creating scalable chatbot systems involves focusing on infrastructure, performance, and preparation for unexpected surges in traffic. Here’s how to approach high-load scenarios effectively.
Serverless Setup Guide
Using a serverless architecture can make scaling OpenAI-powered chatbots much easier.
-
Infrastructure Configuration
Set parameters like memory, timeout, and concurrency to match the anticipated workload. -
API Gateway Integration
- Use an API gateway with WebSocket support.
- Add request throttling and enable automatic scaling.
- Implement caching to handle repetitive queries efficiently.
-
Connection Management
Limit connection pooling by setting appropriate pool size, idle times, and timeouts.
This setup ensures smooth prompt processing and efficient token usage.
Prompt Performance Tuning
Improving prompt performance can significantly enhance the chatbot's responsiveness. Here are some tips:
- Optimize context to reduce token usage.
- Enable response streaming to reduce perceived latency.
- Strike a balance between detailed context and processing speed.
These adjustments help maintain efficiency, even during peak usage.
High Traffic Backup Plans
Prepare for traffic spikes with a solid backup strategy:
-
Traffic Management Tiers
- Normal load: All features remain active.
- Heavy load: Turn off non-essential features.
- Critical state: Deliver cached responses only.
-
Fallback Mechanisms
Use static response caching and queuing systems to handle high-load situations seamlessly. -
Recovery Protocol
Implement auto-scaling, circuit breakers to prevent overloading, and a gradual service restoration process.
For critical deployments, tools like OpenAssistantGPT come with built-in high availability and auto-scaling features, making them a great addition to these strategies.
OpenAssistantGPT Platform Guide
OpenAssistantGPT is a platform that lets you create and embed AI-powered chatbots without writing code. Using OpenAI's Assistant API, it offers simple customization and integration options for deploying chatbots at scale.
Features Designed for Growth
OpenAssistantGPT is built to handle scaling with ease, offering tools and features that streamline the process:
- No-Code Chatbot Creation: Build and customize chatbots effortlessly.
- Web Crawling for Updates: Automatically extract content from the web to keep chatbot responses up to date.
- File Analysis: Analyze multiple file formats, like CSV, XML, and images, to enhance chatbot replies.
- Secure Authentication: Protect private deployments with SAML/SSO login options.
- SDK Integration: Seamlessly integrate with frameworks like NextJS and deploy on platforms such as Vercel.
Flexible Service Plans
OpenAssistantGPT offers multiple pricing tiers to meet various needs, from small projects to enterprise-level operations:
| Feature | Basic Plan ($18/month) | Pro Plan ($54/month) | Enterprise Plan (Custom Pricing) |
|---|---|---|---|
| Chatbots | 9 | 27 | Unlimited |
| Crawlers | 9 | 27 | Unlimited |
| Files | 27 | 81 | Unlimited |
| Actions | 9 | 27 | Unlimited |
| Custom Domains | – | 5 | Unlimited |
| Messages | Unlimited | Unlimited | Unlimited |
The Enterprise plan includes additional perks, such as SAML/SSO authentication, service-level agreements (SLAs), and priority support for demanding environments.
How to Integrate OpenAssistantGPT
Follow these steps to integrate OpenAssistantGPT into your workflow:
-
API Integration
- Set up authentication and retrieve your API keys.
-
Deployment Setup
- Use the provided SDK to connect with NextJS and deploy on Vercel.
-
Performance Monitoring
- Track performance using built-in analytics tools to ensure the chatbot operates smoothly as your needs grow.
Conclusion
Key Points for Scaling
Scaling OpenAI chatbots requires careful attention to infrastructure, API management, queue systems, and monitoring. Here's what matters most:
- Optimize infrastructure: Use reliable cloud resources, load balancers, and caching systems to handle sudden traffic increases.
- API usage: Keep an eye on rate limits and use request batching to improve efficiency and control costs.
- Queue systems: Implement strong queuing and asynchronous processing to ensure smooth operations during high demand.
- Monitoring: Regularly track performance to identify and address bottlenecks before they impact the system.
These points provide a solid foundation for scaling effectively.
Implementation Checklist
-
Infrastructure Setup
Set up cloud resources, caching, and load balancers to handle traffic efficiently. -
API Optimization
Monitor rate limits, batch requests, and use retry mechanisms to improve performance. -
Traffic Management
Use message queues, asynchronous processing, and fallback responses to keep operations running smoothly. -
Monitoring Configuration
Install monitoring tools, configure alerts, and create dashboards to track performance. -
Platform Integration
Choose the right service tier, configure authentication, and set up failover procedures.
Incorporate these steps into your scaling strategy to ensure your chatbot can handle peak usage without issues.